【シリーズ】機械学習をベースにDXの仕事を考えてみよう~1.データの可視化

何はともあれ、機械学習を行うための元になるデータを確認するところから始めます。
今回は、時系列データの予測を対象に考えてみます。
そのために、データを時間軸で整形する必要があります。
データ整形のポイント
機械学習を、Pythonで行うことを前提にするなら、データを、CSV形式のファイルするのが好都合です。
日本で、データをCSVファイルにする場合、列名に日本語が含まれていることはよくあります。
この日本語が曲者で、最近なら、utf-8形式でCSVファイルを作ることをお勧めしますが、従来のWindows環境でファイルを作ると、Shift-JISで作成されることもあります。
このような場合にも対応するPythonコードを作成することは可能ですが、それらも含めてポイントを列挙してみます。
- CSVファイルのエンコードはUTF-8が望ましい
- 最初に列は、日時データとする
- 日時データ間隔は、統一すること(欠損時間があってもよい)
- 時系列が複数に別れている場合は、1つにマージが望ましい
- 予測対象データ(目的変数)と影響を与えるデータ(説明変数)を明確にできるとよい
Python実行環境
Pythonの実行環境は、本来なんでもよいです。しかし、今後の機械学習でのモデル生成や、ディープラーニングを行う場合、計算能力が求められる場合もあります。
また、Python実行環境を変更しても、比較的同じ状態で利用できるプラットフォームで行えることを考えておく方がよいです。
そういうことなから、Jupyter Notebookは、便利な環境だと思います。
Windows PCでも動作しますし、Google Colaboratoryでも使えます。
Google Colaboratoryは、Google Driveにデータを置いて、Pythonコードでデータ処理が行えます。
しかも、無料で利用を開始できます。CPU/GPUリソースが沢山必要になれま、有料版への移行もできます。
データ置き場としてのGoogle Driveも15GBまでなら無料ですし、それ以上必要になっても、比較的安価に、ディスクサイズを拡張できます。
この『【シリーズ】機械学習をベースにDXの仕事を考えてみよう』では、Google Colaboratoryで作業を行うものとして、書いていきます。
Google Coraboratoryを使うために
- 1. Google Coraboratoryを使うために、Googleアカウントを準備しましょう。
次のリンクで、Google アカウントの作成 の説明を参照できます。
2. Googleアカウントで、Googleへログイン(Google検索画面を開きログイン)できたら、以下のメニューを開き、「ドライブ」を選択します。

3. Google ドライブの画面が開くと、「マイドライブ」を開き、作業フォルダを作成し、そこにCSVファイルを置きます。
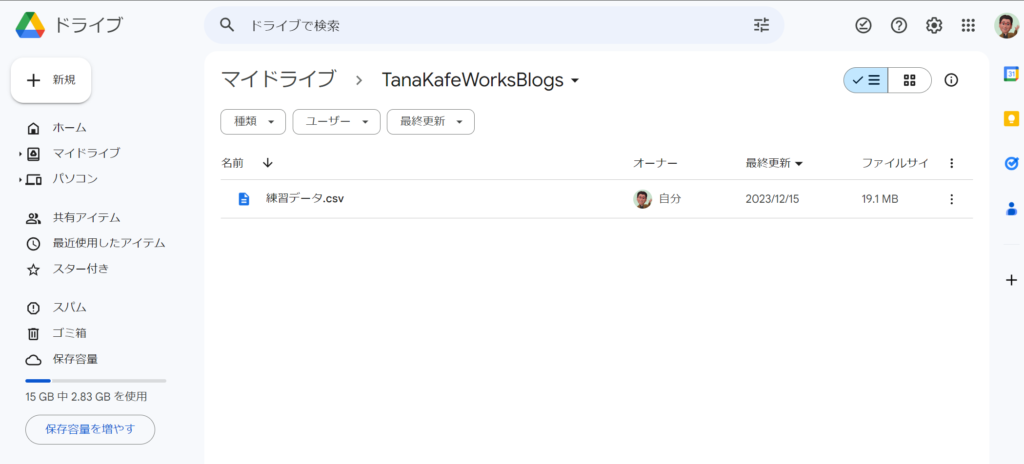
4. フォルダを右クリックして、メニューを開き、「Google Coraboratory」を選択しPython環境を準備します。
この環境は、Jupyter Nodebookと同じです。
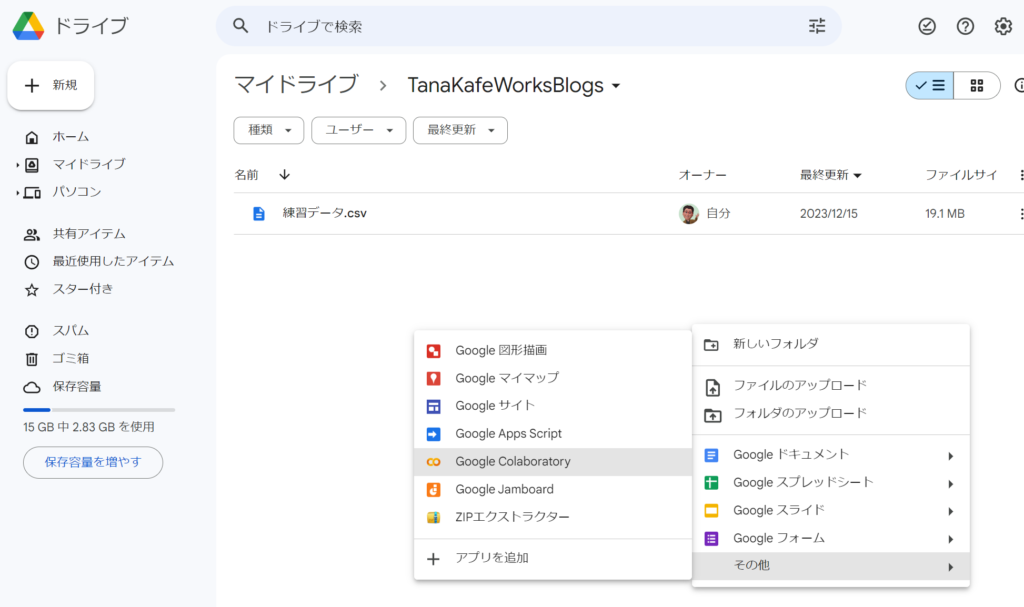
5. Jupyter Notebookのファイルができます。
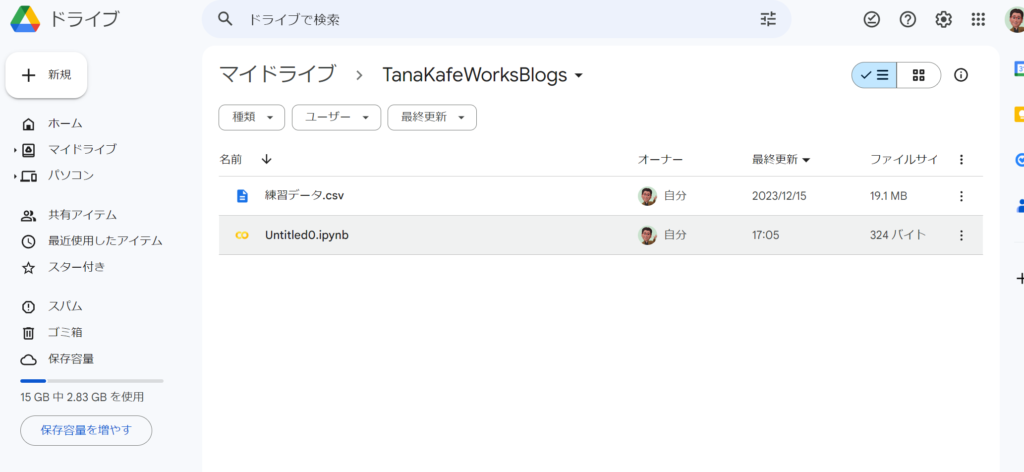
6. Jupyter Notebookのファイルの名前を変更しておきましょう
最初は、「Untitled0.ipynb」という名前です。そのフィールドにマウスを当てて、名前を「練習.ipynb」のように自由に変更してください。
「練習.jpynp」に変更後
Google Coraboratory特有のこと
Jupyter Notebookとほとんど同じとはいえ、Googleドライブの割当てや、日本語表示への対応など、Google Colaboratory特有の「おまじない」的なことが必要です。
ここでは、Pythonコードに追加しておいた方がよいコードを紹介します。
Googleドライブへのアクセス
Googleドライブ置いたCSVファイルを使用するために、MyドライブをGoogle ColaboratoryのPythonコードからアクセスするために、Jupyter Notebook実行セルに次のコードを追加します。
# Google Driveの "MyDrive"をマップ
from google.colab import drive
drive.mount('/content/drive')データプロット時に日本語表示のために
Google Colaboratoryのグラフのプロットに、matplotlibを使用しますが、日本語文字列の表示が、□になります。
原因は、デフォルトでは日本語文字のフォントが登録されていないことによるものです。
日本語表示を行うために、次のコードを追加します。
# 日本語フォントのインストール
!apt-get -y install fonts-ipafont-gothic
# Matplotlibのキャッシュをクリア
#!rm /root/.cache/matplotlib/fontlist-v330.json
# Matplotlibのキャッシュをクリア
!rm -rf /root/.cache/matplotlib/
# Matplotlibを最新に更新
!pip install matplotlib --upgrade
!pip install japanize-matplotlib
import japanize_matplotlibここからが本番!!
時系列データを使い、未来の状況を予測するために、統計的手法、機械学習、ディープラーニングなど色々な方法があります。
これらの方法で予測モデルを作るにあたり、まずは、元になる時系列データを観察することから始めます。
観察するとは、時系列データをグラフにプロットして、傾向らしきものがありそうかどうかを見当をつけることです。
プロットに含めるデータ:
- 予測すべき対象のデータ列(目的変数)※必須
- 予測に関係するデータ列(説明変数)※明確でなくれば、可能性のあるものをピックアップ
説明変数が明らかであれば、それは予測に必須としてプロットします。
仮に、予測対象に何が関係しているかが不明確であれば、経験的に関係しそうなデータを対象としておきます。
収集データの種類が多い場合は、ある程度絞り込みを行うことをお勧めします。
目的変数と相関関係の高いデータを説明変数とするのが、統計手法や機械学習では一般的です。
ディープラーニングは、説明変数を限定しないほうが、効果的なモデルを作れる場合があります。
ここでは、まず最初に、CSVファイルを元に、Pythonのnumpyやpandasの外部ライブラリを使い、データを観察するために、グラフにプロットする手順をご紹介します。
目的変数/説明変数をプロットしてみよう!
時系列データを、時間軸(X軸)に、目的変数と説明変数をY軸にプロットして、観測値を可視化すると、性質が見えてくる場合がありますので、最初に観測データをグラフ化する手順を説明します。
説明するために、サンプルがありと便利なので、UCI電力使用量データを使い説明します。
この「UCI 機械学習リポジトリ」は、機械学習アルゴリズムの実証分析のために機械学習コミュニティによって使用されるデータベース、ドメイン理論、データ ジェネレーターのコレクションで、次のライセンスにより利用が許諾されています。
このデータセットは、クリエイティブ コモンズ表示 4.0 インターナショナル (CC BY 4.0) ライセンスに基づいてライセンスされています。
データ入手先:https://archive.ics.uci.edu/dataset/374/appliances+energy+prediction
データ:
目的変数=Appliances
説明変数=とりあえず、T_out(気温)、lights(照明)※適当です
| 列名 | 説明 | 単位 |
| date | 日付時刻 | 年-月-日 時:分:秒 |
| Appliances | 家電、エネルギー使用量 | Wh |
| lights | 照明、家の照明器具のエネルギー使用量 | Wh |
| T1 | キッチンエリアの温度 | 摂氏 |
| RH_1 | キッチンエリアの湿度 | % |
| T2 | リビングルームエリアの温度 | 摂氏 |
| RH_2 | リビング ルームの湿度 | % |
| T3 | ランドリールームエリアの温度 | 摂氏 |
| RH_3 | ランドリールームエリアの湿度 | % |
| T4 | オフィスルームの温度 | 摂氏 |
| RH_4 | オフィス室内の湿度 | % |
| T5 | バスルームの温度 | 摂氏 |
| RH_5 | 浴室内の湿度 | % |
| T6 | 建物の外(北側)の温度 | 摂氏 |
| RH_6 | 建物の外 (北側) の湿度 | % |
| T7 | アイロン室の温度 | 摂氏 |
| RH_7 | アイロン室の湿度 | % |
| T8 | ティーンエイジャールーム 2 の温度 | 摂氏 |
| RH_8 | ティーンエイジャーの部屋 2 の湿度 | % |
| T9 | 両親の部屋の温度 | 摂氏 |
| RH_9 | 両親の部屋の湿度 | % |
| T_out | 気温度 (Chievres 気象観測所から) | 摂氏 |
| Press_mm_hg | 気圧 (Chievres 気象観測所から) | mmHg |
| RH_out | 屋外の湿度 (Chievres 気象観測所から) | % |
| Windspeed | 風速 (シエーブル気象観測所から) | m/s |
| Visibility | 視程 (キエーブル気象観測所から) | km |
| Tdewpoint | T露点 (チーヴル気象観測所から) | °C |
| rv1 | 確率変数 1 | 無次元 |
| rv2 | 確率変数 2 | 無次元 |
このデータを使い、電気使用量に影響を与える部屋や外部気温の関係を視覚化してみましょう。
実際に処理を行うPythonコードは、今後の為に、設定コードと、実行コードに分けて作成しておきます。
プロット対象に対する情報を設定
前述の、「Googleドライブへのアクセス」と「データプロット時に日本語表示のために」を実行ステップに組み込み実行しておきます。
その後、プロットする対象を次の実行ステップとして実行します。
# 対象ファイル指定
file_path = '/content/drive/MyDrive/TanaKafeWorksBlogs/energydata_complete.csv'
# 対象期間指定
target_start_date_time = '2016/01/25'
target_end_date_time = '2016/2/5'
# プロット対象列の範囲を指定
target_column_start = 1
target_column_end = 5
# 特定の時間範囲でフィルタリング
highlight_start = '2016/1/25 17:00'
highlight_end = '2016/2/05 18:00'file_pathには、Googleドライブに置いたCSVファイルを指定します。
対象期間のtarget_start_date_timeとtarget_end_date_timeには、CSVファイルの日時のなかで、プロット対象となる開始と終了の値をYYYY/MM/DD形式で指定します。
CSVのプロット対象範囲の列番号を1からnを、target_column_startとtarget_column_endに指定します。
実際には、連続でなく、目的変数に相当する列名、説明変数に相当する列名を指定することになります。
この範囲は、コードに記載しますので、ここでは、まずは、グラフが表示できるかを確認するために、適当にしてしてください。
予測すべき対象(目的変数)で、事象が発生した範囲を、「# 特定の時間範囲でフィルタリング」で指定します。
これで、グラフで、フォーカスしている点が背景色により識別しやすくできます。
プロットのためのコード
import pandas as pd
#import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.patches as patches
from pandas.plotting import register_matplotlib_converters
import numpy as np
# Matplotlibを再インポートしてキャッシュを再構築
# import matplotlib
# matplotlib.font_manager._rebuild()
# 日本語フォントを設定
plt.rcParams['font.family'] = 'IPAexGothic'
# mpl.rcParams['font.family'] = 'TakaoPGothic' # または他の日本語フォント
register_matplotlib_converters()
# CSVファイルを読み込む際に、まずはutf-8エンコードで試す
try:
df = pd.read_csv(file_path, encoding='utf-8')
except UnicodeDecodeError:
# utf-8で読み込みに失敗した場合は、shift_jisエンコードで試す
df = pd.read_csv(file_path, encoding='shift_jis')
# Convert the date column to datetime
df['date'] = pd.to_datetime(df['date'])
# デモンストレーション用に列のサブセットを選択する
# columns_to_plot = df.columns[target_column_start:target_column_end]
# 特定の列を抽出
columns_to_plot = [col for col in df.columns if 'Appliances' in col or 'lights' in col or 'T_out' in col]
# プロット
plt.figure(figsize=(15, 10))
# 対象日時フィルタ
filtered_df = df[(df['date'] >= target_start_date_time) & (df['date'] <= target_end_date_time)]
# カラム名一覧
# DataFrameの全カラム名をリストとして取得
column_names = df.columns.tolist()
# カラム名のリストを表示
# print(column_names)
# カラム名を要素ごとに改行して表示
for column in column_names:
print(column)
# Defining distinct colors for the plot lines
colors = ['red', 'green', 'blue', 'purple', 'orange']
# 'viridis'カラーマップから色を生成
# colors = plt.cm.viridis(np.linspace(0, 1, 20))
# colors = plt.cm.plasma(np.linspace(0, 1, 20))
# colors = plt.cm.inferno(np.linspace(0, 1, 20))
# Plotting the data with distinct colors and highlighting the specified range
for i, column in enumerate(columns_to_plot):
plt.plot(filtered_df['date'], filtered_df[column], label=column, color=colors[i % len(colors)])
# Adding a highlighted area for the specified time range
plt.gca().add_patch(patches.Rectangle((mdates.date2num(pd.to_datetime(highlight_start)), plt.ylim()[0]),
mdates.date2num(pd.to_datetime(highlight_end)) - mdates.date2num(pd.to_datetime(highlight_start)),
plt.ylim()[1] - plt.ylim()[0], color='yellow', alpha=0.3))
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y/%m/%d %H:%M'))
plt.gca().xaxis.set_major_locator(mdates.HourLocator(interval=1))
plt.gcf().autofmt_xdate() # Rotation
plt.legend()
plt.title('Sample Graph for 2016/1/25 - 2/5 with Distinct Colors')
plt.xlabel('Date')
plt.ylabel('Values')
plt.grid(True)
plt.show()コードを実行すると。次のようなグラフが表示できます。
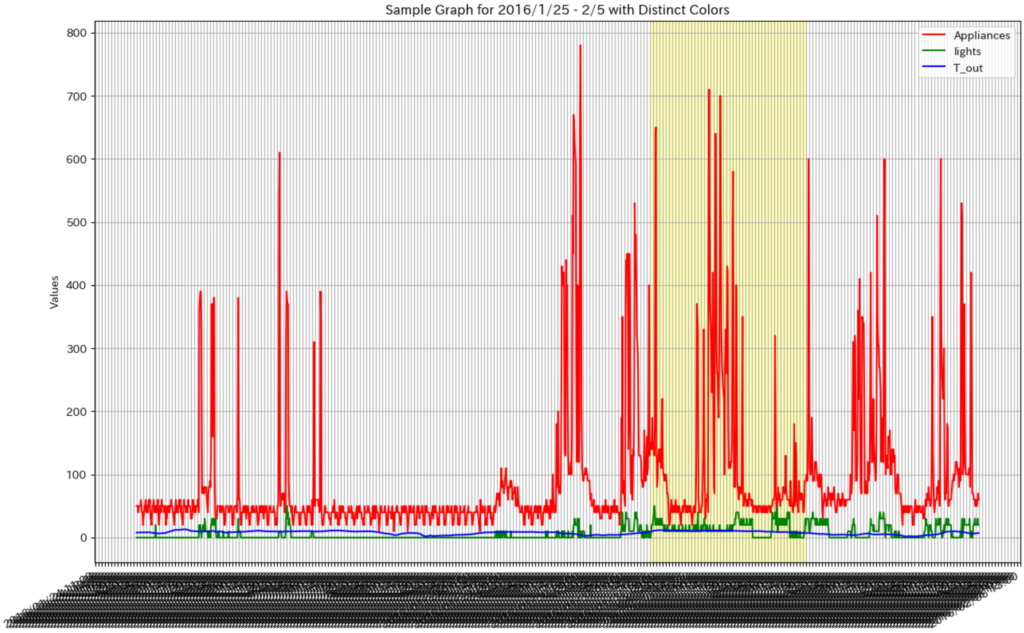
原データの値を確認するには、データ表示期間や対象となる値を適切に調整し、統計処理や機械学習に使えるデータへ整えていく必要がありますが、ここで示したように全体をグラフ化してみると、よいと思います。
この例では、Appliancesだけが、値のスケールが大きく違うので、1つのグラフにすると状況を把握しにくいです。
例えば、Appliancesを別グラフとして、X軸を揃えて上下に並べてみるコードは、次のようになります。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.patches as patches
from pandas.plotting import register_matplotlib_converters
# CSVファイルを読み込む際に、まずはutf-8エンコードで試す
try:
df = pd.read_csv(file_path, encoding='utf-8')
except UnicodeDecodeError:
# utf-8で読み込みに失敗した場合は、shift_jisエンコードで試す
df = pd.read_csv(file_path, encoding='shift_jis')
# 日付カラムをdatetime型に変換
df['date'] = pd.to_datetime(df['date'])
# 特定の期間でフィルタリング
filtered_df = df[(df['date'] >= target_start_date_time) & (df['date'] <= target_end_date_time)]
# 対象となる列の選択
columns_to_plot = ['Appliances', 'lights', 'T_out']
# 色の定義
colors = ['red', 'green', 'blue']
# プロット設定
plt.figure(figsize=(15, 10))
# 上のグラフ(Appliancesのみ)
ax1 = plt.subplot(2, 1, 1)
ax1.plot(filtered_df['date'], filtered_df['Appliances'], label='Appliances', color='red')
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y/%m/%d %H:%M'))
ax1.xaxis.set_major_locator(mdates.HourLocator(interval=1))
plt.gcf().autofmt_xdate()
ax1.legend()
ax1.set_title('Appliances Over Time')
ax1.set_xlabel('Date')
ax1.set_ylabel('Values')
ax1.grid(True)
# 下のグラフ(lightsとT_out)
ax2 = plt.subplot(2, 1, 2)
for i, column in enumerate(columns_to_plot[1:]):
ax2.plot(filtered_df['date'], filtered_df[column], label=column, color=colors[i + 1])
ax2.xaxis.set_major_formatter(mdates.DateFormatter('%Y/%m/%d %H:%M'))
ax2.xaxis.set_major_locator(mdates.HourLocator(interval=1))
plt.gcf().autofmt_xdate()
ax2.legend()
ax2.set_title('Lights and T_out Over Time')
ax2.set_xlabel('Date')
ax2.set_ylabel('Values')
ax2.grid(True)
# ハイライト領域の追加
highlight_start_num = mdates.date2num(pd.to_datetime(highlight_start))
highlight_end_num = mdates.date2num(pd.to_datetime(highlight_end))
for ax in [ax1, ax2]:
ax.add_patch(patches.Rectangle((highlight_start_num, ax.get_ylim()[0]),
highlight_end_num - highlight_start_num,
ax.get_ylim()[1] - ax.get_ylim()[0], color='yellow', alpha=0.3))
# グラフの表示
plt.tight_layout()
plt.show()実行結果は、次のようになり、かなり見やすくなります。
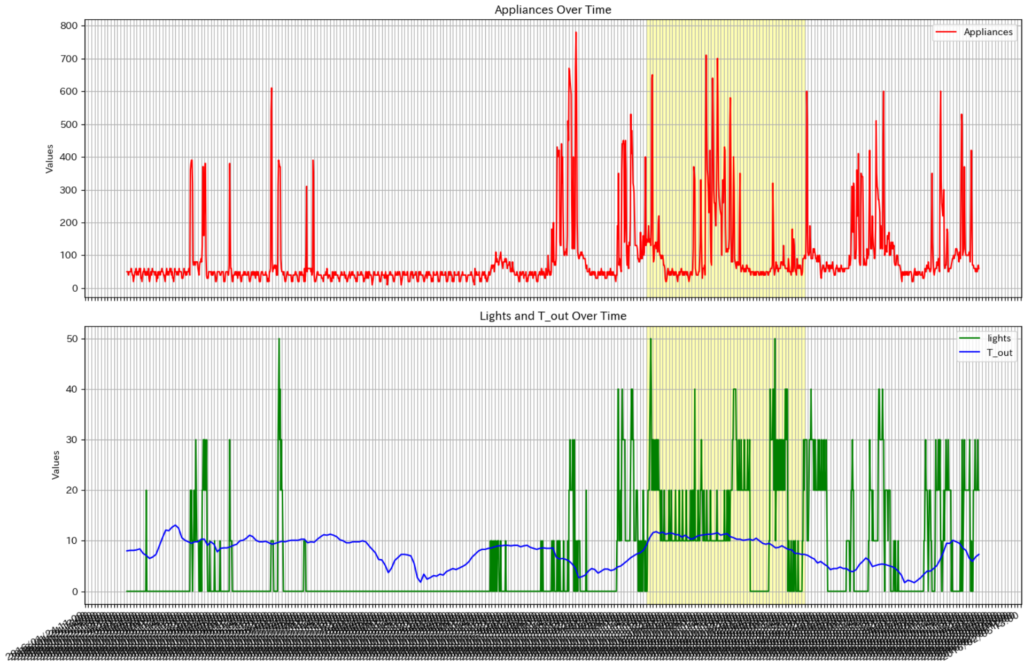
ちなみに、これらのPythonコードは、ChatGPTを使い生成したものです。
必ずしも、1回で完全なコードが生成できるわけではありませんが、何度か指示を与えれば、期待したコードを生成してくれます。
もう少し、「プロット対象に対する情報を設定」をパラメータ化して、対象列名を変数化するとより汎用的なコードにできます。
まずは、原データをグラフでプロットする方法をご紹介しました。